A班
『手話通訳者にかわる聴覚障害者と健常者の相互コミュニケーション支援』
班長:松本 知浩
班員:伊藤 良彰
神前
松本 圭
目的:手話通訳者にかわる聴覚障害者と健常者の相互コミュニケーション支援
研究理由:日本には焼く36万人の聴覚障害者が存在する。しかし現在、1000人程度の手話通訳者しかおらず、またいつでも通訳者を介することもできず、聴覚障害者の日常コミュニケーションには、口話や筆談を余儀なくされている。また通訳者を介する場合でもプライバシーの問題が関わってくる。本研究では、それらを解決する手段として、手話通訳ロボットを作成することを目的とする。
システム概要:ロボットを介してのコミュニケーションは数のように行われる。
![]()
![]()
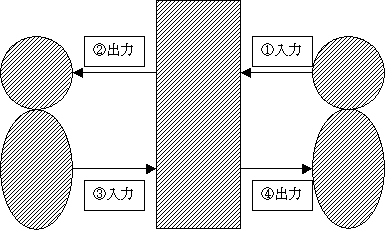

手話通訳ロボット
①音声入力(音声認識)
音声認識の技術は進んでいて、既に多数のソフトウェアが存在し言語変換の能力は高い。したがって、音声認識に必要とされるツールは音声データベースと認識ソフトウェアとそれらをおさめるハードとマイクである。
②手話出力
手話出力はモニターから多関節をもつ3次元モデルの手話アニメーションを映し出すことで行う。手話アニメーションの作成は後述する手話認識の技術を併用してデータを取り入れて行う。単語間に不連続が応じるので線形補正行う。
③手話入力
手話を認識することはある意味このシステムにおける最もロボットらしい一面である。なぜなら人間にとって人のジェスチャーから意味をとりだすのは容易だが、機械は映像から直接意味を認識するのはほぼ不可能である。そこでセンサーから取り入れる情報を自身で絞り込みコード化してデータベースの中から最も適当な意味をとりだすというものだ。またセンサーは一つではなく、複数のモーションキャプチャーでそれぞれ分担して情報の入力を行う。手話のデータをデータベース化することで認識することで認識・生成に応用できる。
手話動作の8割が意思伝達の主たる部分で残りの2割が感情や微妙なニュアンスを表す。モーションキャプチャーは接触型(データグローブ)と非接触型(画像検出)があるが我々はなるべく非接触型を使う方針でいった。接触型は正確だが装着によっておこる様々な問題が起こりうるので、非接触型で接触型に劣らない正確さを目指す。ステレオビデオカメラでとりいれた画像全体から特徴抽出を行う。具体的には原画像から肌色だけを抽出して座標抽出をおこなう。得られたデータから肩幅を基準とするX,Y座標を個々に設定することで、あらかじめ決められた座標データを個人にあわせた座標データに修正をする。修正された座標データから主要箇所にマーカーをつけジェスチャーの開始位置や終了位置とその間マーカーが描く軌跡を解析する。。顔や指の形状解析は鼻や目から目標となる顔を画像からみつけだし、そこに向けたLEDの反射光を利用したセンサーで3次元に詳しく取り出す。教育させていくことで自身の会話に必要なデータだけを増やしていく。
④音声出力
従来の音声出力を利用する。必要なのはソフトとスピーカー。
※ベンチャー用の文
手話翻訳ロボットが実現すれば、聴覚障害者とのコミュニケーションを容易にするだけでなく、たとえばこれを応用することで手話通訳のないテレビやラジオから手話の映像として情報を提供することが可能になる。これを小型化することで様々な場所で使えるようになることを目指す。